
| Master software performance in just 16 hours! Join our Software Optimization for the Memory Subsystem Workshop taking place from May 18th to May 21st. Click here to express interest or register. |
In our experiments with the memory access pattern, we have seen that good data locality is a key to good software performance. Accessing memory sequentially and splitting the data set into small-sized pieces which are processed individually improves data locality and software speed.
In this post, we will present a few techniques to improve the memory access pattern and increase data locality. The advantage of this approach is that the changes are localized in the algorithm itself, i.e. there is no need to change the data layout1 or the memory layout2. The disadvantage is that the algorithms often become more difficult to understand and modify.
The Techniques
The techniques we propose here mostly apply to the processing of simple data types (int, doubles, chars). The techniques loop interchange and loop tiling are used to optimize loop nests3. Another technique, loop sectioning, is used to optimize two consecutive simple (non-nested) loops which are typically seen with vectorization.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
Loop Interchange
Loop interchange is an optimization technique you can apply to many codes doing simple data type processing in nested loops (e.g. matrices or images). Nested loops often pop up as hot loops because they typically have the highest algorithmic complexity. To illustrate loop interchange, have a look at the matrix multiplication example:
void matmul(double* c, double* a, double* b, int n) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
for (int k = 0; k < n; k++) {
c[i][j] += a[i][k] * b[k][j];
}
}
}
}Matrix multiplication consists of a loop nest with three perfectly nested loops and the Add-Multiply statement in the innermost loop. To determine if the loop nest would benefit from loop interchange, we need to do the access pattern analysis for all the variables in the innermost loop. To do this, we observe what the next memory access will be when the iterator variable of the innermost loop (in our case k) changes value (in our case increases by one):
- When
kincreases by 1, the address ofc[i][j]doesn’t change. Therefore, this is constant access. - When
kincreases by 1, the address ofa[i][k]increases by 1. Therefore, this is sequential access. - When
kincreases by 1, the address ofb[k][j]increases byn. In this case, thenis the stride and we call this access strided access.
When it comes to software performance, sequential accesses are preferred to strided accesses. So, any transformation that eliminates strided accesses will result in performance improvements.
We could eliminate strided accesses using loop inerchange. Loop interchange works by exchanging the outer and inner loops in a loop nest. For example, we could exchange the loops over j and k. In that case, the loop over j would become the inner loop, and the loop over k the outer loop. That being said, the source code looks like this:
void matmul(double* c, double* a, double* b, int n) {
for (int i = 0; i < n; i++) {
for (int k = 0; k < n; k++) {
for (int j = 0; j < n; j++) {
c[i][j] += a[i][k] * b[k][j];
}
}
}
}If we do the memory access pattern analysis for this loop nest, the access to the variable c[i][j] is sequential, the access to the variable a[i][k] is constant and the access to the variable b[k][j] is also sequential. We managed to get rid of strided memory accesses completely!
For loop interchange to actually make sense, you need to analyze the type of access for each variable before and after the interchange. If the result is a decrease in the number of strided or random accesses and an increase in the number of sequential and constant accesses, loop interchange should generally be beneficial to performance. For this kind of analysis, you can use automatic tools; one such is Codee.
To perform the loop interchange, the loops need to be perfectly nested, i.e. all the statements should be in the innermost loop. If this is not the case, then moving the offending statements into separate loops needs to be done prior to loop interchange. Here is a short example to demonstrate it:
void loop_interchange(double* b, double* a, int n) {
for (int i = 0; i < n; i++) {
double sum = 0.0;
for (int j = 0; j < n; j++) {
sum += a[j][i];
}
b[i] = 0.1 * sum;
}
}The memory access pattern of variable a[j][i] is strided, and it could be converted to sequential with loop interchange. However, the loops are not perfectly nested. We can fix this by converting the variable sum to an array.
void loop_interchange(double* b, double* a, int n) {
double* sum_arr = malloc(n * sizeof(double));
for (int i = 0; i < n; i++) {
sum_arr[i] = 0.0;
for (int j = 0; j < n; j++) {
sum_arr[i] += a[j][i];
}
b[i] = 0.1 * sum_arr[i];
}
free(sum_arr);
}With these modifications, we can move everything blocking the perfect loop nesting to separate loops and then perform the interchange:
void loop_interchange(double* b, double* a, int n) {
double* sum_arr = malloc(n * sizeof(double));
for (int i = 0; i < n; i++) {
sum_arr[i] = 0.0;
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
sum_arr[i] += a[j][i];
}
}
for (int i = 0; i < n; i++) {
b[i] = 0.1 * sum_arr[i];
}
free(sum_arr);
}From the original one loop we end up with three loops, but the second loop dominates the runtime because of its higher algorithmic complexity (O(n2) vs O(n)). Now it is possible to perform the loop interchange. The critical loop nest looks like this:
void loop_interchange(double* b, double* a, int n) {
...
for (int j = 0; j < n; j++) {
for (int i = 0; i < n; i++) {
sum_arr[i] += a[j][i];
}
}
...
}The memory access pattern of the variable sum_arr[i] is sequential (originally it was constant) and the memory access pattern of the variable a[i][j] is also sequential (originally strided). The loop is strided accesses free!
Loop interchange is the first technique to consider when speeding up loop nests. Speedups of 10x are not uncommon. If the loops are not perfectly nested, you can use techniques like loop peeling or loop fission to make them perfectly nested. Because of the improvement of the memory access pattern, the compiler will often vectorize such loops, which results in additional speedup.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
Loop Tiling
Another technique used to speed up the processing of memory-bound loop nests is loop tiling (or loop blocking). In the case of loop tiling, a large n-dimensional dataset is broken into many smaller n-dimensional datasets called tiles or blocks, and each tile is processed separately from one another. The size of the tile should be picked such that it fits nicely with the L1 data cache. This will allow the fastest possible data access.
So, when does it make sense to apply loop tiling? There are two somewhat distinct scenarios. The first scenario happens when for one reason or another, you cannot eliminate the strided memory access through loop interchange. Consider the example of rotating a gray image by 90 degrees:
void rotate_image(char* b, char* a, int n) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
b[i][j] = a[j][i];
}
}
}Loop interchange doesn’t help in this case, as there will always be one strided memory access pattern regardless of the innermost loop. However, there is a way to improve the memory subsystem utilization for this even in the presence of strided accesses.
Notice that, because the whole cache line is brought from the memory to the data cache, after accessing a[j][i] we can access a[j][i + 1]cheaply, since these two pieces of data belong to the same cache line. The problem in our case is that if n is large, access to a[j][i + 1] will come much after a[j][i] and by that time a[j][i + 1] will be evicted from the data cache.
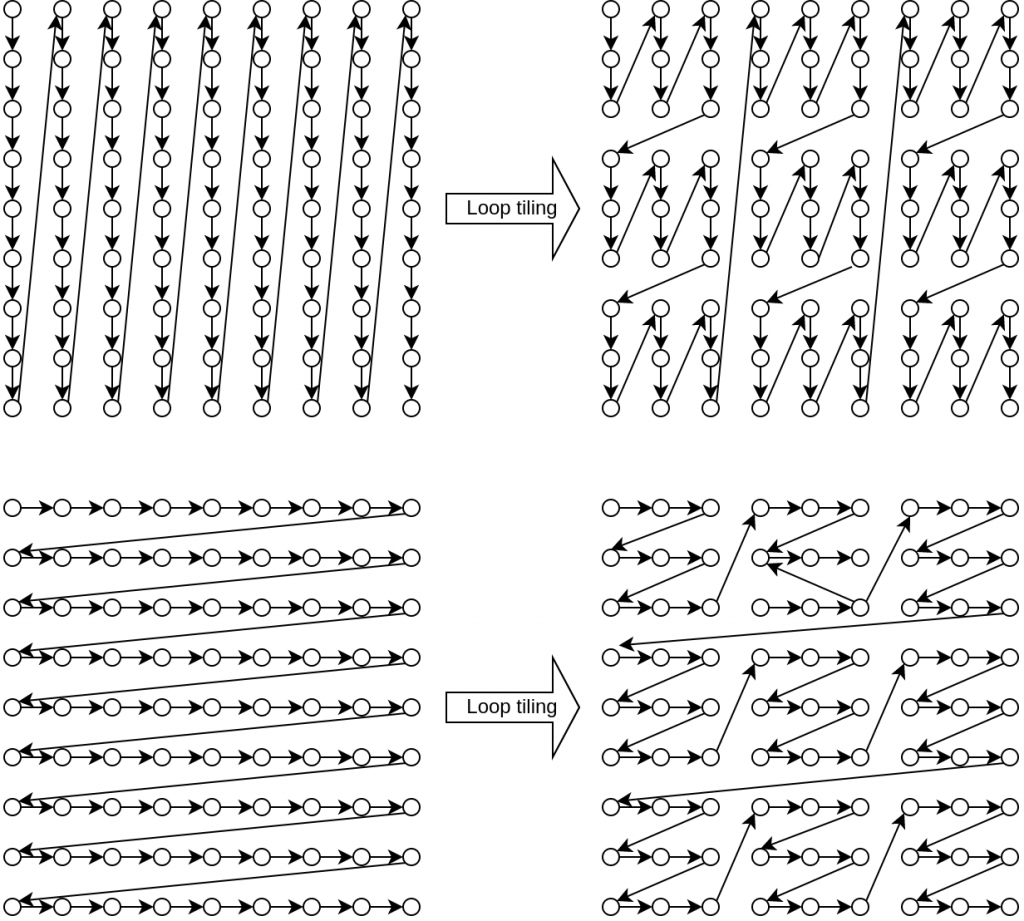
The solution is loop tiling, i.e. instead of processing one huge matrix column by column, we break the matrix into smaller pieces called tiles and process them instead. If the tile fits the L1 cache, this will guarantee better memory subsystem utilization. We rewrite our code to rotate the image in tiles, like this:
void rotate_image(char* b, char* a, int n) {
const int TILE_SIZE = 64;
for (int ii = 0; ii < n; ii += TILE_SIZE) {
for (int jj = 0; jj < n; jj += TILE_SIZE) {
int i_end = MIN(ii + TILE_SIZE, n);
int j_end = MIN(jj + TILE_SIZE, n);
for (int i = ii; i < i_end; i++) {
for (int j = jj; j < j_end; j++) {
b[i][j] = a[j][i];
}
}
}
}
}This code is more memory subsystem friendly and faster than the original code, even though it is executing more instructions and doing more work.
Another use case for loop tiling is when you don’t have strided accesses, only constant and sequential accesses, but you are iterating over the same data many times. Consider the example of interchanged matrix multiplication from the loop interchange section:
void matmul(double* c, double* a, double* b, int n) {
for (int i = 0; i < n; i++) {
for (int k = 0; k < n; k++) {
for (int j = 0; j < n; j++) {
c[i][j] += a[i][k] * b[k][j];
}
}
}
}If you look closely at this code, you will see that each value a[i][k], b[k][j] and c[i][j] will be accessed n times. If the value of n is large, then the three matrices will not fit the L1 data cache and will need to be brought from other parts of the memory subsystem many times. The solution is again loop tiling, where we split the data set into smaller tiles and process them independently.
void matmul(double* c, double* a, double* b, int n) {
const int TILE_SIZE = 64;
for (int ii = 0; ii < n; ii++) {
for (int kk = 0; kk < n; kk++) {
for (int jj = 0; jj < n; jj++) {
int i_end = MIN(ii + TILE_SIZE, n);
int j_end = MIN(jj + TILE_SIZE, n);
int k_end = MIN(kk + TILE_SIZE, n);
for (int i = ii; i < i_end; i++) {
for (int j = jj; j < j_end; j++) {
for (int k = kk; k < k_end; k++) {
c[i][j] += a[i][k] * b[k][j];
}
}
}
}
}
}
}Loop tiling is done according to the same partitioning scheme as previously. With a good selection of constant TILE_SIZE, the whole tile can fit the L1 data cache which should result in maximum speedup.
Loop tiling is not for the faint of heart and comes with several limitations:
• Picking the correct number for the value TILE_SIZE. Too small and the loop is inefficient. Too large and it doesn’t fit the data caches anymore. Also, it might happen that the value for TILE_SIZE is not constant for all matrix sizes and data types.
• Vectorization. Loop tiled loops are more difficult for automatic compiler vectorization. If you do perform loop tiling, but the runtime hasn’t gotten better, check the executed instruction counter (you can use LIKWID for this). If the instruction number has grown dramatically, your program is not executing vectorized code anymore and that’s the reason for no speed improvement. Your code is not memory bound anymore, but it is core bound. The only way to fix this is to rewrite the segment of code using compiler intrinsics.
• Readability. After loop tiling, the code gets quite messy.
Loop tiling will only work for large datasets that do not fit the L1 cache. Smaller datasets will not benefit from loop tiling; in fact, they can become slower due to the increase of looping overhead.
No compiler in our knowledge performs loop tiling, although loop tiling is possible to perform automatically. Again, Codee is the only tool we are aware of that will detect opportunities for loop tiling.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
Loop Sectioning
Background
Although vectorization is not the topic of this post, vectorization is often used to achieve top performance. One of the ways to achieve vectorization is to split a loop into a vectorizable and non-vectorizable part. Have a look at the following example:
void distance(point_t* p1, point_t* p2, float pivot, float* smaller, float* larger, size_t n) {
for (size_t i = 0; i < n; i++) {
// Calculate distance square between p1[i] and p2[i]
float x_diff = p1[i].x - p2[i].x;
x_diff *= x_diff;
float y_diff = p1[i].y - p2[i].y;
y_diff *= y_diff;
float distance = x_diff + y_diff;
// Place the distance square in one of two buckets
if (distance < pivot) {
smaller[smaller_size] = distance;
smaller_size++;
} else {
larger[larger_size] = distance;
larger_size++;
}
}
}In this example, we have two arrays of points, p1 and p2. In the hot loop, the first part of the loop (lines 4-8) calculates the square of the distance between pairs of points.4 In the second part (lines 11-17), we put the calculated distance in one of the arrays, either smaller or larger, depending on its value.
This kind of loop would be faster if vectorized, but vectorization is not possible in this case because of the second part. The second part is essentially a loop-carried dependency. However, it is possible to vectorize if we split this loop into two loops in the process of loop fission.
To perform loop fission, we split the original loop into two loops. The first loop will be vectorizable, the second won’t. But because computations are localized in the first loop, the overall effect on performance is positive. After loop fission, the code looks like this:
for (size_t i = 0; i < n; i++) {
float x_diff = p1[i].x - p2[i].x;
x_diff *= x_diff;
float y_diff = p1[i].y - p2[i].y;
y_diff *= y_diff;
distance_vec[i] = x_diff + y_diff;
}
for (size_t i = 0; i < n; i++) {
float distance = distance_vec[i];
if (distance < pivot) {
smaller[smaller_size] = distance;
smaller_size++;
} else {
larger[larger_size] = distance;
larger_size++;
}
}We use a new temporary array called distance_vec (line 6) to store the results calculated in the first loop to use them in the second loop (line 10). The newly introduced array increased memory consumption. The first loop will get automatically vectorized, the second will not. But due to partial vectorization, the overall benefit for the software performance will be positive.
The problem with this approach happens if the value of n, i.e. the loop trip count is large. When n is large, the values written to distance_vec in the first loop will be evicted from the caches and will need to be reread from the memory in the second loop. Since the second loop does very little computation, rereading data will make it slower.
Loop Sectioning to Improve Data Locality
To mitigate this problem, we resort to loop sectioning. Loop sectioning is very similar to loop tiling, except that loop sectioning works on one-dimensional array. The idea is simple: instead of processing the first loop from begging to end, followed by the second loop from beginning to end, we process them in sections. We pick a number called SECTION_SIZE, and divide the data set into parts, each of them (except for the last) of a given section size. Then we alternate between the first and the second loop by running them on sections instead of the whole data set. Here is loop sectioning applied to our example:
for (size_t ii = 0; ii < n; ii += SECTION_SIZE) {
size_t max_i = std::min(n, ii + SECTION_SIZE);
for (size_t i = ii; i < max_i; i++) {
float x_diff = p1[i].x - p2[i].x;
x_diff *= x_diff;
float y_diff = p1[i].y - p2[i].y;
y_diff *= y_diff;
distance_vec[i - ii] = x_diff + y_diff;
}
for (size_t i = ii; i < max_i; i++) {
float distance = distance_vec[i - ii];
if (distance < pivot) {
smaller[smaller_size] = distance;
smaller_size++;
} else {
larger[larger_size] = distance;
larger_size++;
}
}
}The outer loop (line 1) iterates over the sections, the two inner loops (lines 3 and 11) iterate inside the sections. By correctly picking the value for SECTION_SIZE, we ensure that the data is always read from the fastest cache.
As with loop tiling, loop sectioning comes with several disadvantages:
- Makes sense to do only for partial vectorization. This kind of transformation doesn’t make sense if both loops are vectorized or none of them are vectorized. In these two cases, it makes sense to merge the two loops into one loop (loop fusion). This completely removes double accesses to the same data and doesn’t need a temporary array.
- Makes sense to do if the second loop is memory bound. In the case of loop sectioning, it is the second loop that benefits from sectioning. If the second loop is computationally bound, the time spent fetching data is masked by computations. In this case, the speedup will be invisible.
- Makes sense to do if the runtimes of both loops are similar or the first loop is faster. As already mentioned, it is the second loop that becomes faster through sectioning. If the first loop’s runtime is much longer than the second loop’s, then the speed improvement in the second loop won’t matter much, because the first loop is the one influencing the runtime.
Loop sectioning has some additional benefits as well: one is a decrease in memory size for the temporary buffer. Another benefit is related to the temporary array. Originally, when we introduced the temporary array, initial access to it would generate a large number of minor page faults. After loop sectioning, because the temporary array is smaller, so is the number of minor page faults. Because of this, loop sectioning can pay off even if, for example, the first loop is much slower than the second (since this can be due to minor faults).
Experiments
All the measurements have been done on Intel(R) Core(TM) i5-10210U CPU and Ubuntu 22.04. We repeated the measurements 10 times and we report here average numbers. The standard deviation is not reported, but it was very small for all the measurements.
Loop Interchange
To measure the effects of loop interchange on performance, we use the same example we used to introduce loop interchange: matrix multiplication. Here is the source code of simple matrix multiplication; you can find the loop the code of interchanged version in the introduction to loop interchange.
void matmul(double* c, double* a, double* b, int n) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
for (int k = 0; k < n; k++) {
c[i][j] += a[i][k] * b[k][j];
}
}
}
}We are measuring runtime, instruction count, CPI and the total memory data transferred for the original version, the interchanged version and the vectorized interchanged version. The matrix size is 1680×1680 doubles (about 21 MB). Here are the numbers:
| Original version | Loop interchanged w/o vectorization | Loop interchanged with vectorization | |
|---|---|---|---|
| Runtime | 19.212 s | 3.797 s | 2.331 s |
| Instruction count | 22,553.8 M | 22,551.0 M | 4,527.2 M |
| CPI | 2.88 | 0.57 | 1.40 |
| Loaded data volume | 52.63 GB | 33.29 GB | 33.17 GB |
| Stored data volume | 0.26 GB | 0.07 GB | 0.097 GB |
Loop interchange turns out to be very powerful for this particular example, resulting in a speed-up of about 5 times. Vectorization boosts this a little bit more, to an overall speedup of more than 8.
If we look at the instruction counts for the original and the interchanged version without vectorization, the numbers are very similar, which suggests that the overall speedup comes from higher hardware efficiency. This is also confirmed using CPI rates, which is much better for the loop interchanged version without vectorization.
Loop interchange improves the memory access pattern and also decreases the amount of data that needs to be fetched from the slower memory subsystems to the faster memory subsystems.
When vectorization is enabled, we get an additional speed boost, but this mostly comes from a decrease in instruction count. The value of CPI 1.4 suggests that this code is still memory bound and can be improved further.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
Loop Tiling
For loop tiling, we start off from the vectorized interchanged version of the previous section. Then we perform loop tiling as we already described when we introduced loop tiling. We found the best runtimes when TILE_SIZE is 48, and we are presenting those results here:
| Original (loop interchanged) | Loop tiled w/o vectorization (TILE SIZE 48) | Loop tiled with vectorization (TILE SIZE 48) | |
|---|---|---|---|
| Runtime | 2.331 s | 1.006 s | 0.834 s |
| Instruction count | 4,527.19 M | 7,440.37 M | 4,067.21 M |
| CPI | 1.40 | 0.524 | 0.77 |
| Load data volume | 33.17 GB | 1.56 GB | 1.47 GB |
| Stored data volume | 0.097 GB | 0.062 GB | 0.066 GB |
The compiler (CLANG) doesn’t vectorize the tiles loops automatically, so we had to do it manually using compiler intrinsics.
Loop tiling causes a dramatic decrease in the amount of traffic between the CPU and the memory. This decrease can be seen in other levels of the memory hierarchy as well (not shown here). Although the tiled version was not vectorized, it was nevertheless 2.3 times faster than the original version. With vectorization, the speed up was even greater: 2.8 times.
This example again shows that the benefits of vectorization are small if the data needs to be fetched from the main memory. The value of CPI 0.77 shows that the algorithm is still not using the hardware perfectly efficiently, so there is still room for improvement.5
Loop Sectioning
For the loop sectioning example, we are using the same example as when we presented the technique in the introduction to loop sectioning. The source code is calculating distances and placing them in one of the two buffers depending on the calculated value. Here is the source code for the original version:
for (size_t i = 0; i < n; i++) {
distance_t x_diff = p1[i].x - p2[i].x;
x_diff *= x_diff;
distance_t y_diff = p1[i].y - p2[i].y;
y_diff *= y_diff;
distance_t distance = x_diff + y_diff;
if (distance < pivot) {
smaller[smaller_size] = distance;
smaller_size++;
} else {
larger[larger_size] = distance;
larger_size++;
}
}The source code for the fissioned and sectioned version you can find in the introduction to loop sectioning section.
In our setup SECTION_SIZE is 1024. We picked this size to make sure the intermediate array fits the L1 cache. The loop trip count is 128M values, as since we are using floats to represent distances and points, the total amount of traffic read from memory for this loop is 2 arrays x 2 floats x 4 bytes per float x 128 M = 2 GB. The total amount of data written to the memory is 1 float x 4 bytes per float x 128 M = 512 MB.
Here are the runtimes, instruction counts, and memory-transferred volumes for all three versions:
| Original | Fission | Sectioning | |
|---|---|---|---|
| Runtime | 0.256 s | 0.234 s | 0.196 s |
| Instruction count | 1744.97 M | 1055.57 M | 1064.95 M |
| CPI | 0.394 | 0.676 | 0.615 |
| Load data volume | 2.911 GB | 3.926 GB | 2.826 GB |
| Store data volume | 0.548 GB | 1.079 GB | 0.542 GB |
When it comes to runtime, the sectioned loop is the fastest, the original loop is the slowest. The fissioned loop is somewhere in between. When it comes to instruction count, the original loop executed the most instructions, since the single hot loop is not vectorized. After fissioning and sectioning, we get two hot loops. The fissioned and sectioned versions execute about 1.65 times less instruction, due to the vectorization of the first loop.
As far as data volume transferred between the memory and the CPU, the original and sectioned loop transfer roughly the same amount of data. The fissioned version transfers more, because the temporary array will get evicted from the memory when the dataset is large. Loop sectioning is actually introduced to remedy this: to keep the vectorization status achieved through loop fission but also to keep the lower memory subsystem utilization that came with the original version.
As you can see, the speed improvements are not huge. The sectioned version is about 1.3 times faster than the original version.
Conclusion
The way we access data is one of the major factors in performance! Although many algorithms naturally access data sequentially, when this is not the case, a performance penalty can be quite large.
In the case of matrix accesses, loop interchange and loop tiling are valuable techniques to improve software performance. Loop sectioning is a bit different because the conditions where it can be successfully applied are narrower, but for an engineer striving for peak performance, it is a useful technique nevertheless.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
- Data layout refers to how data is organized into structs or classes. [↩]
- Memory layout refers to how the memory chunks representing data are stored in memory. [↩]
- We use the term loop nest to designate several nested loops as a whole [↩]
- Distance squares can be used instead of actual distances when comparing distances because they are cheaper to compute – no need for calculating a square root. [↩]
- If you know how to make it faster and you are willing to write for this blog, I will be more than happy to guest publish your post here. [↩]
I found your post to be very informative and well-written. You have a real talent for explaining complex topics in a way that’s easy to understand.
Thank you.