A story of a very large loop with a long instruction dependency chain.

A story of a very large loop with a long instruction dependency chain.

This post has a second part, the same problem is solved differently. Read more. In this post we investigate long dependency chains: when an instruction depends on the previous instruction depends on the previous instruction… We want to see how long dependency chains lower CPU performance, and we want to measure the effect of interleaving…

As I already mentioned in earlier posts, vectorization is the holy grail of software optimizations: if your hot loop is efficiently vectorized, it is pretty much running at fastest possible speed. So, it is definitely a goal worth pursuing, under two assumptions: (1) that your code has a hardware-friendly memory access pattern1 and (2) that…

For all the engineers who like to tinker with software performance, vectorization is the holy grail: if it vectorizes, this means that it runs faster. Unfortunately, many times this is not the case, and the results of forcing vectorization by any means can mean lower performance. This happens when vectorization hits the memory wall: although…

We use matrix multiplication example to investigate loop interchange and loop tiling as techniques to speed up your program that works with matrices.
A post explaining how a few small changes in the right places can have a drastic effects on performance of an image processing algorithm named Canny.
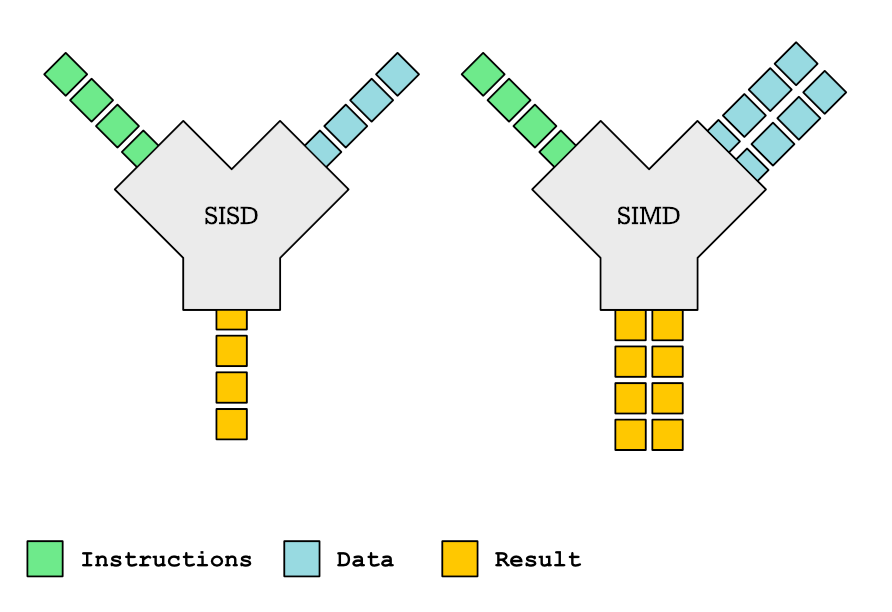
This is the first article about hardware support for parallelization. We talk about SIMD, an extension almost every processor nowadays has that lets you speed up your program.