We investigate how to make faster hash maps, trees, linked lists and vector of pointers by changing their data layout.

We investigate how to make faster hash maps, trees, linked lists and vector of pointers by changing their data layout.
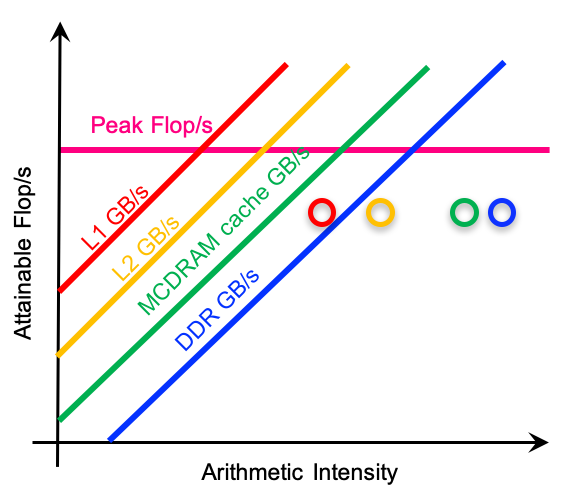
In this post we introduce a few most common tools used for memory subsystem performance debugging.

We investigate the secret connection between class layout and software performance. And of course, how to make your software faster.

In this post, we are investigating a few common ways to decrease the number of memory accesses in your program.

We investigate techniques of frugal programming: how to program so you don’t waste the limited memory resources in your computer system.

In our experiments with the memory access pattern, we have seen that good data locality is a key to good software performance. Accessing memory sequentially and splitting the data set into small-sized pieces which are processed individually improves data locality and software speed. In this post, we will present a few techniques to improve the…

We continue the investigation from the previous post, trying to measure how the memory subsystem affects software performance. We write small programs (kernels) to quantify the effects of cache line, memory latency, TLB cache, cache conflicts, vectorization and branch prediction.

In this post we investigate the memory subsystem of a desktop, server and embedded system from the software viewpoint. We use small kernels to illustrate various aspects of the memory subsystem and how it effects performance and runtime.
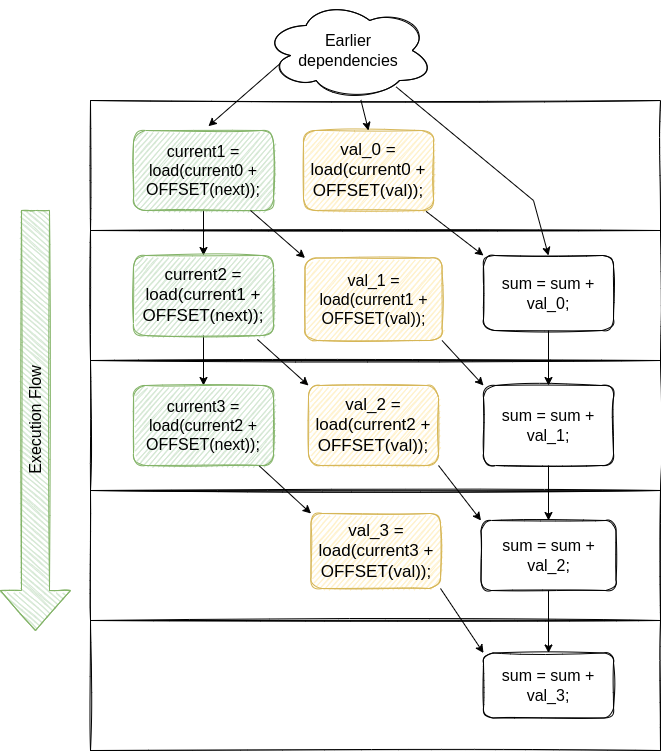
We talk about instruction level parallelism: what instruction-level parallelism is, why is it important for your code’s performance and how you can add instruction-level parallelism to improve the performance of your memory-bound program.

We investigate how memory consumption, dataset size and software performance correlate…