| Master software performance in just 16 hours! Join our Software Optimization for the Memory Subsystem Workshop taking place from May 18th to May 21st. Click here to express interest or register. |
In the previous post we’ve covered parallel algorithms, and we talked about what kind of problems does parallelism efficiently solve. This time we will talk about what hardware resources developers have at their disposal to achieve parallelism, what are the benefits and limitations of each of them. Today on the menu is SIMD.
SIMD (single instruction multiple data) parallelism
SIMD parallelism is nothing new and all desktop CPUs and many embedded CPUs have it nowadays. The CPUs implement SIMD parallelism through SIMD instructions. Compared to regular instructions, a SIMD instructions (short for Single Instruction Multiple Data) processes more than one piece of data. A standard, scalar load to a register will load a single value, instruction add will add a single value from one register to another, etc. On the other hand, a SIMD load will load several values to a special SIMD register; a vector add instruction will add together several values, etc.
To illustrate this, consider the following scalar loop:
for (int i = 0; i < N; i++) {
A[i] = B[i] + C[i];
}In this loop we iterate over three arrays and adding the value of the arrays B and C to array A.
If we were to parallelize this code with SIMD, the code would translate to the following version:
for (int i = 0; i < N; i+=4) {
vec4 B_tmp = load4(B + i); // Loads 4 integers into a SIMD register B_tmp
vec4 C_tmp = load4(C + i);
vec4 A_tmp = add4(B_tmp, C_tmp); // Adds together vectors of four integers
store4(A_tmp, A + i); // Stores four integers
}The CPU has a load instruction that can load four (or eight, or sixteen) consecutive values at once to a special SIMD register. Then it performs add on two SIMD registers which actually runs four additions in parallel. In the end, storing four results is also done in parallel. Note that each of these operations correspond roughly to one instruction.
Everything in this example is very performance efficient; loading, adding, and storing four values happens at the same time it would take for a regular scalar version operating on one value to complete.
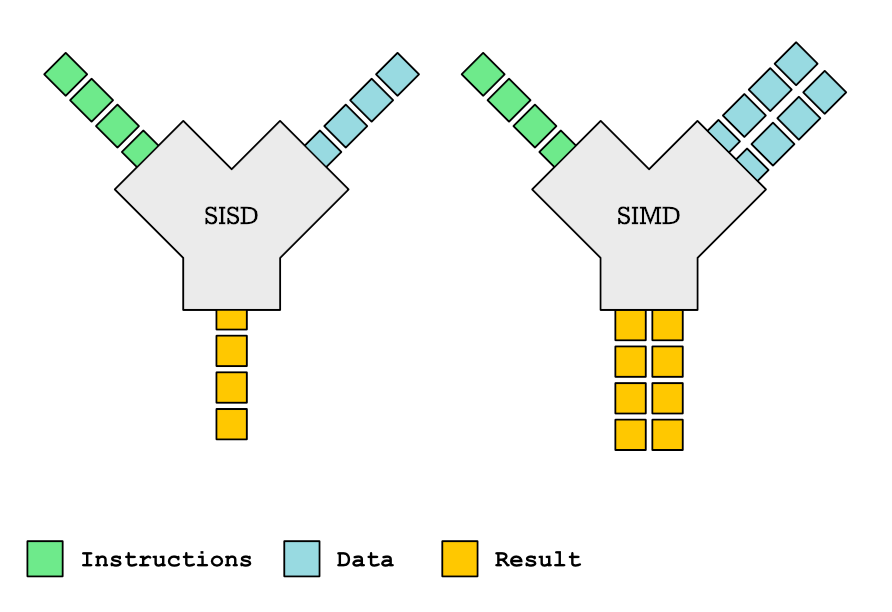
Typically, the CPU has a fixed size SIMD register: 128 bits (SSE), 256 bits (AVX), or 512 bits (AVX512). For example, SSE SIMD on x86 processor can process 2 doubles or 4 ints or 8 shorts or 16 chars. The smaller the type you are processing, the more parallelism can be extracted. In 2020, modern desktop CPUs will typically have SIMD width of 256 bits, high-end server CPUs will have a width of 512 bits. Embedded CPUs mostly have a width of 128 bits.
SIMD Advantages
There are few good things about SIMD. The first is that it is available on almost all CPUs. Only really low-end embedded CPUs will be without SIMD nowdays.
The second is that SIMD is really the cheapest way to perform parallelization. Other parallelization techniques, such as multithreading or offloading to a graphic card come with a “warm-up” cost. When your input is small, it might cost you more to start threads or copy data to the graphic card than to do the actual computation.
And the last, but the most important thing, the compilers can automatically generate SIMD instructions for various loops in your programs in a process called autovectorization, without any intervention on your side. Compiling with high-level optimization settings (-O3 on most compilers) turns on autovectorization. Note that not all loops will be vectorized, and this depends on many factors: loop carried dependencies, conditional statements in the loop body, data memory layout, etc.
Autovectorization is an important topic for a performance engineer. Unfortunately, the compilers are conservative when it comes to vectorization and they will sometimes miss vectorization opportunities.1 On the upper side, the developer can often help the compiler by restructuring the code so effective vectorization can take place. We will cover autovectorization in one of the upcoming posts.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
SIMD Drawbacks
SIMD become popular with MMX extensions to Pentium processors at the end of the 90s. The idea was to speed up graphical applications: applications where the program would apply the same transformation to the stream of data. These include: decoding and encoding images and videos, 3D graphics, processing audio, machine learning, etc. So this is the area where SIMD really shines and where the performance advantages are the greatest.
Of course SIMD can be used for other applications as well, but often it happens that there are no speed improvements with SIMD and in those cases the compilers switches back to scalar code.
Here are a few examples of SIMD drawbacks: cases where SIMD is impossible to use or inefficient.
Drawback: Management of conditionals
The first drawback is related to how SIMD handles if clauses in your program. Consider the following example:
for (int i = 0; i < N; i++) {
if (A[i] >= 1) {
A[i] = A[i] - B[i];
}
}SIMD doesn’t have a concept of branching, but this is often simulated using bit masking. The above loop translates to the following SIMD sequence:
vec4 ones = { 1, 1, 1, 1 }
for (int i = 0; i < N; i+= 4) {
vec4 A_tmp = load4(A + i);
vec4 B_tmp = load4(B + i);
// Calculates the result for each element in the vector,
// even those that won't be needing it.
vec4 res = sub4(A_tmp, B_tmp);
// Calculates the predicate, i.e. those elements of the
// vector that will load the new value
vec4<bool> greater_than_one = operator>=(A_tmp, ones);
// Conditional load: loads the new value only for those
// elements where greater_than_one is true.
A_tmp = load_if_condition(A_tmp, greater_than_one);
store4(A_tmp, A + i)
} As you can see, the SIMD version of the loop translates to calculating A[i] - B[i] both when needed and not, and then filtering out those that are unneeded in load_if_condition.
If you have complicated nested ifs inside your loop body, your program will need to calculate all the operations inside each of ifs body and then filter out the irrelevant result. This makes SIMD much less useful, so the compilers will generally opt for non-SIMD versions of those loops. There are several ways to remove branches we already covered earlier and most of those techniques are applicable with SIMD.
Drawback: can efficiently process only simple types
The second drawback of SIMD is that it can only process simple types such as integers, floats, shorts, and small classes with two to four members of the same type. So, if your algorithm searches for data in a binary tree, performs hash map lookups, etc, SIMD will be useless in these scenarios. With other parallelization techniques you could run several searches simultaneously, but not with SIMD (or at least, not easily).
Drawback: memory layout is important
If you are C++ developer following an object-oriented paradigm, you predominantly use classes as types. Even though, classes consist of simple types: integers, floats, etc, SIMD is of little use in this kind of environment. Consider the following example:
class student {
std::string name;
double average_mark;
};
double calculate_average_mark(const std::vector<student>& students) {
double sum = 0.0;
for (int i = 0; i < students.size(); i++) {
sum += students[i].average_mark;
}
return sum / students.size();
}The code consists of a class student with two fields: name and an average_mark. It also consists of a function calculate_average_mark which takes the array of student instances and calculate the average mark of all students.
Let’s assume that the sizeof(std::string) is eight, and size(double) is also eight. In a vector of class student, float values containing the average mark are non-consecutive, i.e. they are located at memory offsets 8, 24, 40, etc. Even though it is possible to use SIMD in this example, most compilers will switch to scalar code because doing SIMD on a non-consecutive memory layout is slow.2
When your program is actually processing data that is important to be processed fast, you can rearrange your data in memory so that it can be processed more efficiently. Game developers have been doing it for years in a paradigm called data-oriented design, that which focuses more on data and operations, and less on abstractions and encapsulations.
The basic idea revolves around using struct-of-arrays instead of array-of-structs. We define a class called students that has two arrays, one for names and one for average marks.
class students {
std::vector<std::name> names;
std::vector<double> average_marks;
double calculate_average_mark() {
double sum = 0;
for (int i = 0; i < average_marks.size(); i++) {
sum += average_marks[i];
}
return sum / average_marks.size();
}
};
The compiler with the right switches will generate SIMD instructions to calculate the average mark since the doubles containing the average marks are laid out sequentially in memory.
The speed difference? Here it is:
As you can see, changing the memory layout made the program run two times faster. Enabling SIMD made the program run again two times faster, so with SIMD and modified memory layout the program ran four times faster than the original.
In light of these numbers it is easy to understand why game developers are running away from the object-oriented paradigm. The game cannot get released if it renders slow, and this simple example demonstrates how OOP is wasteful to the resources.
Drawback: cannot vectorize code with loop carried dependencies and pointer aliasing
Consider the following loop:
for (int i = 1; i < n; i++) {
a[i] = a[i] + a[i - 1];
}This loop cannot be vectorized because it contains a loop carried dependency. The value of a[i] depends on the value of a[i - 1] which has only been calculated in the previous iteration. So why do loop carried dependencies prevent vectorization?
Let’s assume that vector instructions work on 4 pieces of data at a time and that a[5] = { 0, 1, 2, 3, 4 }. After the loop completes, the result is a[5] = { 0, 1, 3, 6, 10 }. In order to vectorize this loop, the compiler would need to load four pieces of data from offset 1, load four pieces of data from offset 0, add them together, and store the result at offset 1.
If the compiler vectorized this code, it would load values { 0, 1, 2, 3 } to one vector register (offset 0) and values { 1, 2, 3, 4 } for the other vector register (offset 1). It then adds two vector registers together, creating the result { 1, 3, 5, 7 } and storing it back together at offset 1. The result is a[5] = { 0, 1, 3, 5, 7 } which is clearly not the correct result. Vectorization is impossible in this case.
There are good news about loop carried dependencies and bad news. The good news is that the codes with true loop carried dependencies are rather rare. The bad news is that the compiler often cannot rule out loop carried dependencies because of pointer aliasing.
Consider the following example:
for (int i = 0; i < n; i++) {
a[i] = a[i] + b[i];
}This code doesn’t have loop carried dependencies and can be safely vectorized. Or maybe it can’t? What happens if the pointers in the code are set like this: b = a - 1?
If this is the case, then there is a loop carried dependency identical to the one in the previous example. The loop is unvectorizable. This is the worst case, but the compiler has to make your code run even in the worst case. So it won’t vectorize this loop.
The compilers are not that dumb, however. The compiler can add a runtime check to establish if there is pointer aliasing, and it can generate two versions of the loop: the vectorized loop for the case where a and b are independent; and a scalar roop for the case of a and b aliasing each other.
If you are sure that your code doesn’t have pointer aliasing, there are a few things you could do to help the compiler:
- Mark all pointers in the code that do not alias each other with the
__restrict__qualifier. The compiler is now free to assume that the particular pointer is point to independent block of memory and can apply vectorization to loops using those pointers. - Tell the compiler to ignore vector dependencies using compiler pragmas. Different compilers have different pragmas for that like
#pragma ivdep,#pragma GCC ivdepor#pragma clang loop vectorize(assume_safety). - Tell the compiler to explicitly vectorize the loop using compiler pragmas. There is an OpenMP SIMD pragma available in most compilers:
#pragma omp simd3. Additionally, compilers have their own pragmas like#pragma clang loop vectorize(enable). These pragmas override the compiler’s cost model analysis and can result in slower code when used improperly.
Final Words
To effectively utilize SIMD, a few requirements need to be met: a loop with a large enough trip count, optimal memory layout, and simple types. And when you have these things in place, with the right compiler switches, the performance of your program will really go off.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
Featured image is taken from Erik Engheim’s RISC-V Vector Instructions vs ARM and x86 SIMD with the permission of the author.
- Because of this, there are special programming languages where the developer can take explicit control over vectorization. One such example is ISPC. [↩]
- This happens because additional instructions called gather instructions needs to be used to collect values from memory to the register, and also because the non-linear memory layout experiences a much larger data cache miss rate [↩]
- To use OpenMP pragmas, you need to pass the –
fopenmp,-fopenmp-simdor a similar compiler switch on the compile line [↩]