We investigate techniques of frugal programming: how to program so you don’t waste the limited memory resources in your computer system.

We investigate techniques of frugal programming: how to program so you don’t waste the limited memory resources in your computer system.

In our experiments with the memory access pattern, we have seen that good data locality is a key to good software performance. Accessing memory sequentially and splitting the data set into small-sized pieces which are processed individually improves data locality and software speed. In this post, we will present a few techniques to improve the…

This post has a second part, the same problem is solved differently. Read more. In this post we investigate long dependency chains: when an instruction depends on the previous instruction depends on the previous instruction… We want to see how long dependency chains lower CPU performance, and we want to measure the effect of interleaving…

We continue the investigation from the previous post, trying to measure how the memory subsystem affects software performance. We write small programs (kernels) to quantify the effects of cache line, memory latency, TLB cache, cache conflicts, vectorization and branch prediction.

In this post we investigate the memory subsystem of a desktop, server and embedded system from the software viewpoint. We use small kernels to illustrate various aspects of the memory subsystem and how it effects performance and runtime.
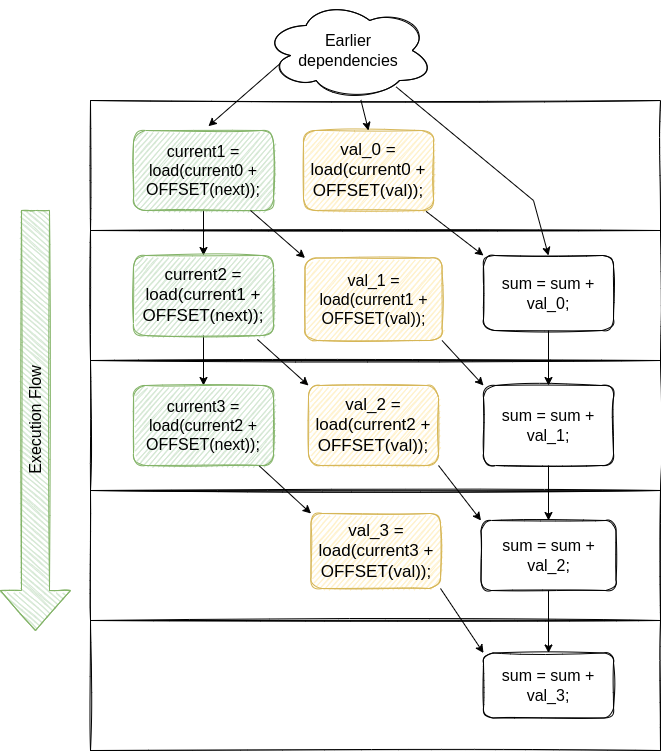
We talk about instruction level parallelism: what instruction-level parallelism is, why is it important for your code’s performance and how you can add instruction-level parallelism to improve the performance of your memory-bound program.

We investigate how memory consumption, dataset size and software performance correlate…

As I already mentioned in earlier posts, vectorization is the holy grail of software optimizations: if your hot loop is efficiently vectorized, it is pretty much running at fastest possible speed. So, it is definitely a goal worth pursuing, under two assumptions: (1) that your code has a hardware-friendly memory access pattern1 and (2) that…

We try to answer the question of why is quicksort faster than heapsort and then we dig deeper into these algorithms’ hardware efficiency. The goal: making them faster.

For all the engineers who like to tinker with software performance, vectorization is the holy grail: if it vectorizes, this means that it runs faster. Unfortunately, many times this is not the case, and the results of forcing vectorization by any means can mean lower performance. This happens when vectorization hits the memory wall: although…