We investigate the unusual way memory subsystem interacts with branch prediction and how this interaction shapes software performance.
We investigate the unusual way memory subsystem interacts with branch prediction and how this interaction shapes software performance.

In this post we investigate how the memory subsystem behaves in an environment where several threads compete for memory subsystem resources. We also investigate techniques to improve the performance of multithreaded programs – programs that split the workload onto several CPU cores so that they finish faster.

In this post we explore how to speed up our memory intensive programs by decreasing the number of TLB cache misses

We investigate how to make faster hash maps, trees, linked lists and vector of pointers by changing their data layout.
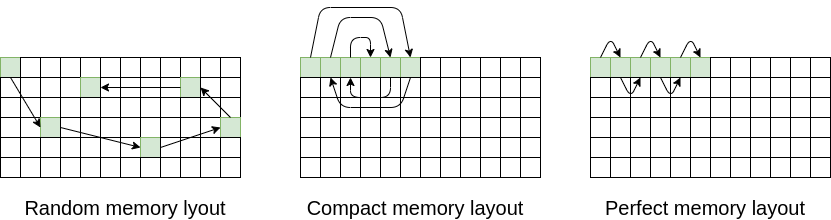
In this post we investigate how we can improve the performance of our memory-intensive codes through changing the memory layout of our performance-critical data structures.
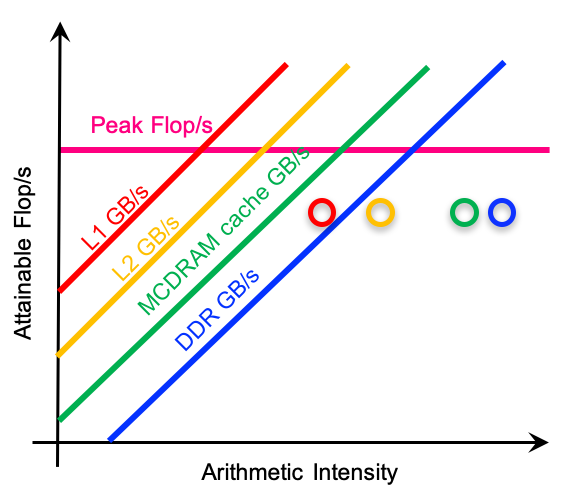
In this post we introduce a few most common tools used for memory subsystem performance debugging.

We investigate techniques for hiding memory latency on in-order CPU cores. The same techniques that the compilers employ.

We investigate the secret connection between class layout and software performance. And of course, how to make your software faster.

We investigate memory loads and stores that the compiler inserts for us without our knowledge: “the compiler’s secret life”. We show that these loads and stores, although necessary for the compiler are not necessary for the correct functioning of our program. And finally, we explain how you can improve the performance of your program by removing them.

In this post, we are investigating a few common ways to decrease the number of memory accesses in your program.