| Master software performance in just 16 hours! Join our Software Optimization for the Memory Subsystem Workshop taking place from May 18th to May 21st. Click here to express interest or register. |
In this post owe continue our ongoing talk about software optimizations for the memory subsystem. We have covered a lot of material up to this point. Feel free to explore the topics.
In this post we will talk about changing the memory layout in order to improve software performance.
What is the memory layout?
We talked about the data layout, which is the way the compiler stores data in the memory. The data layout is known at the compile time. In contrast to this, we use the term memory layout to describe how memory chunks returned by the allocator (implementation of malloc and free) are arranged in memory.
Take for example a linked list. A linked list consists of nodes, and each node holds a value and a pointer to the next node. When we create a linked list, for each of its nodes we ask for a memory chunk from the system allocator. These nodes are somehow arranged in memory. Here is an example of three possible arrangements for the same linked list:
The arrangments of memory chunks have a large influence on software performance, as we will explore in this post.
How does memory layout influence performance?
The influence of memory layout is most visible with data structures that allocate many small data chunks, notably trees and linked lists. The data structure has its logical ordering, for example, a linked list node has a previous and next value, or a tree node has a parent node and two or more children nodes. So, while we are accessing our node, the next node we will be accessing is mostly known in advance.
The basic tenet of good memory performance is what is accessed together should be stored together. In the case of our linked lists and trees, we can increase access performance by storing logically neighboring chunks in physically neighboring memory addresses.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
How can we control the memory layout?
Memory layout can be controlled by overriding the implementation of malloc and free or new and free. This override can be made in three places: by replacing the whole system allocator, using a per-type allocator or using a per-instance allocator
Replacing the System Allocator
Replacing the system allocator means replacing the implementation of malloc and free for all the components in the program. Implementations of malloc and free are part of the standard library, but they can be overwritten.
The original system allocator might not be the best one for your purpose, and it can make sense to replace it. There exist a few implementations of system allocators, such as jemalloc (from Facebook), mimalloc (from Microsoft) and tcmalloc (from Google).
Replacing the allocator is very low effort and will typically result in a speed-up of about a few percent on memory-intensive applications. To replace it, you can either link against the new allocator library, or, if on Linux, use the LD_PRELOAD environment variable to replace the allocator. For example, here is how we replaced the allocator in our tests:
LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libtcmalloc_minimal.so.4 ./my_program
Per-Type Allocator
Instead of replacing the whole system allocator, we can replace the allocator for all the instances of a single type. This makes sense for types that allocate one memory chunk per instance. For example, std::string allocates at most one memory chunk per instance. In standard C++ classes, we can force the class to allocate through a custom allocator instead of a system allocator by overriding the std::allocator template parameter.
Here is how we declare a string with a custom allocator:
using alloc_string = std::basic_string<char, std::char_traits<char>, CustomAllocator<char>>;
alloc_string my_string("Johnnysswlab");Per-Instance Allocator
If we have large data structures that allocate many memory chunks (e.g. a large tree), instead of using a per-type allocator we can use a per-instance allocator. Each type instance gets its own allocator, and each instance allocates its memory chunks from its own memory block.
In C++17 standard library, per-instance data structures can be implemented using polymorphic memory resources. So, for example, instead of using std::map you would be using std::pmr::map. Here is an example of using std::pmr::map with a custom allocator:
std::vector<std::pair<int, int>> buffer(1024*1024);
std::pmr::monotonic_buffer_resource mbr{buffer.data(), buffer.size()};
std::pmr::polymorphic_allocator<std::pair<int, int>> pa{&mbr};
std::pmr::map<int, int> my_map{pa};In the above example, the data is allocated from a vector which is 1 M elements in size. Polymorphic memory resources are a complex topic with their advantages and disadvantages. If they don’t work for you, you can implement your data structures manually.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
Techniques
Replacing the Allocator
In general, replacing the allocator increases data locality, decreases memory fragmentation and increases memory access performance.
For system allocators: just replacing the default system allocator with a custom system allocator can result in a speed-up of about 5% on memory-intensive apps. It is definitely the first option worth investigating for allocation-intensive applications, because of its simplicity.
Implementing a per-instance or per-type allocator requires more work, but has additional advantages: it improves data locality even further because all the data can be allocated from a single memory block, and it allows for additional optimizations we are going to describe in the following few sections. Also, custom allocators can often be implemented without the overhead of chunk bookkeeping.
Compared to a system allocator, per-instance and per-type allocators can be much simpler, even trivial. If all the chunks are of the same size, then the allocator can simply keep all the freed memory chunks in a single linked list. Or, for a per-instance allocator, an implementation can have a no-operation free, where the memory is returned to the operating system once the allocator is destroyed.
Linked List Memory Layout
Each node in a linked list has a logical predecessor and successor. While we are traversing a linked list, we can move one-dimensionally, either forward or backward. If the neighboring nodes are stored in neighboring memory chunks, this can significantly improve the performance. Here we call this memory order perfect. We measure the performance of such linked lists in the experiments section.
Creating and maintaining such a linked list is not an easy thing, though. If the linked is inserted only on one side (e.g. end), we can use a custom per-instance allocator to ensure that successive calls to malloc return successive memory chunks. But if there is a need to insert data anywhere, or to repeatedly modify the linked list, then it the perfect memory layout will slowly deteriorate and performance will be lost. In this case you can perform defragmentation – create a copy of the original linked list but with a perfect memory layout.
Binary Tree Memory Layout
In the case of binary trees, the problem of memory layout is more complex than with linked lists. A node in a binary tree has one predecessor and two successor. But computer’s memory is one-dimensional, therefore we cannot have that a parent, child1 and child2 are all neighbors in memory for all nodes in a tree.
To improve the access performance of binary tree access, we can modify its memory layout in two ways:
- One-Child Neighbor Layout – a tree memory layout, where parent node and one child node (left or right) are neighbors in memory. If the access to the data in the tree is random, we have a 50% chance of hitting a neighboring memory chunk when accessing a child of a parent node.
- Van Emde Boas Layout – a memory layout where a parent, left child and right child, a total of three nodes are three neighboring memory chunks in memory. Most commonly the three chunk ordering parent, left child, right child, but other layouts are possible, e.g. left child, parent, right child.

In all cases that we measured, Van Emde Boas Layout was faster than One-Child Neighbor Layout.
The problems we have seen with linked lists remain here as well. If the tree is modified a lot, we cannot maintain the special memory layout and the performance slowly gets worse. We can remediate this in the same way as with linked list, with defragmentation.
Graphs
A graph is a generalization of a tree, where a node can have an arbitrary number of predecessors and successors. Nevertheless, the same principles can be applied to graphs as with trees. If a node has N logical neighbors, then memory chunks holding the nodes should be neighbors in memory as well.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
Experiments
In the experiments section we are going to measure the impact of various types of memory layouts and allocators on performance of linked lists and trees. We repeated each measurement five times and report the average numbers. The benchmarks were performed on Intel(R) Core(TM) i5-10210U system, with TurboBoost off. The source code is available here.
Linked List Layout
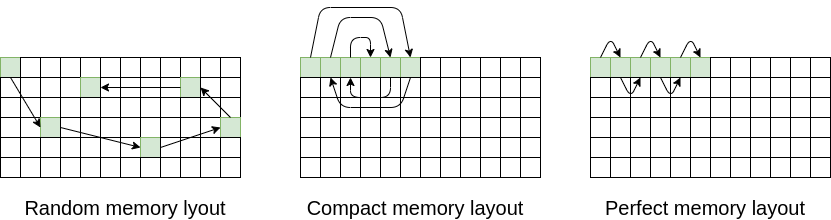
To measure the effect of memory layout performance, we use a linked lists with three memory layouts:
- Random memory layout – the memory chunks corresponding to linked lists nodes are stored in memory with no particular order.
- Compact memory layout – the memory chunks for the linked list nodes are allocated from a single block of memory, therefore, they are closer to one another compared to the random memory layout
- Perfect memory layout – with perfect memory layout, logically neighboring linked lists nodes are also neighboring memory chunks.
Here is a visualization of all three memory layouts:
Compact memory layout and perfect memory layout can only be achieved using a custom per-instance allocator. We measured the time needed to iterate the linked list for all three layouts and for three different linked list sizes: small (128 doubles), medium (1M doubles) and large (64M doubles). The total number of nodes passed in each case is 64M. Here are the results:
| Linked List Size | Random Layout | Compact Layout | Perfect Layout |
|---|---|---|---|
| Small (128 doubles) | 0.18 s | 0.175 s | 0.175 s |
| Medium (1M doubles) | 8.294 s | 6.733 s | 0.218 s |
| Large (64M doubles) | 14.211 s | 10.891 s | 0.221 s |
For small linked list sizes, when the data is mostly fetched from the L1 cache, the layout is unimportant. But for medium and large linked list sizes, the story is very much different. The perfect layout can be hundred times faster than the other two layouts.
Binary Tree Memory Layout
For the binary tree memory layout experiment, we test three memory layouts:
- Random Layout – memory chunks corresponding to the binary tree nodes are stored in memory with no particular order.
- Left Child Neighbor Layout – for each node, the memory chunk corresponding to its left child is a direct neighbor in memory.
- Van Emde Boas Layout – a memory layout where a parent, left child and right child, a total of three nodes are three neighboring memory chunks in memory.
Here is a visualization of all three memory layouts:
We measure the time needed to perform 10 million lookups on large trees with all three layouts (38 MB in size for each tree). We use three types of allocators: the default allocator that comes with the standard library, a Google’s drop-in replacement for the standard allocator and a very simple custom allocator with no metadata. Here are the benchmarking results:
| Allocator Type | Random Layout | Left Child Neighbor Layout | Van Emde Boas Layout |
|---|---|---|---|
| Standard Library Allocator | 7040 ms | 4892 ms | 4571 ms |
| Tcmalloc | 6642 ms | 4425 ms | 4343 ms |
| Custom Allocator | 6710 ms | 4496 ms | 4211 ms |
Although the results are not as drastic as compared to the linked list runtime, nevertheless we see improvements of for Van Emde Boas Layout and Left Child Neighbor Layout over Random Layout. The speedup is about 1.5x.
Final Words
Modifying memory layout is also one of the ways to improve data locality, decrease memory fragmentation and increase memory access performance. It comes in three levels of difficulty.
The easy level is simply replacing the system allocator. It is fairly easy and can lead to a modest improvement in performance.
The medium level is changing the memory layout by allocating all the data from a single block of memory. It is a bit more involved because it requires some rewrite. By the way, this technique is also used in real-time system where memory allocation times must be predictable.
The hard level is creating a data structure with a perfect memory layout. For this, you will need to write your data structure yourself, and then you need to pay attention not to break the perfect memory layout. It pays off in cases where the data structure is mostly read-only and its access performance is very important. Otherwise, the overhead of maintaining such a data structure can outweigh the benefits.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
What performance exactly is measured here? Is it time taken to iterate over the data structure?
You are right! Thanks for noticing, I updated the post with the missing information.