Does it matter if we are compiling with optimizations off (O0) or optimizations on (O3) if the problem is memory bound? Let’s find out…

Does it matter if we are compiling with optimizations off (O0) or optimizations on (O3) if the problem is memory bound? Let’s find out…

This is the last memory optimization that we are covering in this blog. You can see the full list of all memory subsystem optimization that we covered earlier here. Definitely a read for anyone who is trying to improve performance of memory intensive software. In this post, we are covering a few remaining optimization techniques…

In this post we talk about memory mechanism that increase memory accesses latency and we explore the techniques to avoid them in latency-sensitive systems.

We explore performance of latency-sensitive application, or more specifically, how to avoid evicting your critical data from the data cache.

We investigate explicit software prefetching, a mechanism software developers can use to prefetch the data in advance so it is ready once the program needs it.
We investigate the unusual way memory subsystem interacts with branch prediction and how this interaction shapes software performance.

In this post we investigate how the memory subsystem behaves in an environment where several threads compete for memory subsystem resources. We also investigate techniques to improve the performance of multithreaded programs – programs that split the workload onto several CPU cores so that they finish faster.

In this post we explore how to speed up our memory intensive programs by decreasing the number of TLB cache misses

We investigate how to make faster hash maps, trees, linked lists and vector of pointers by changing their data layout.
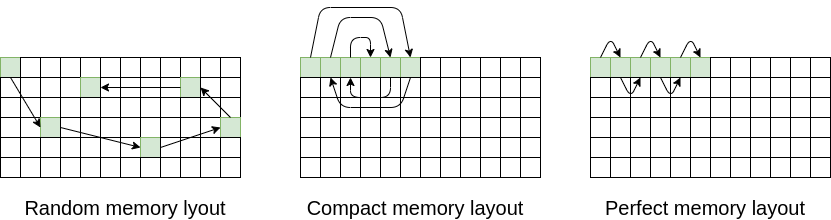
In this post we investigate how we can improve the performance of our memory-intensive codes through changing the memory layout of our performance-critical data structures.