| Master software performance in just 16 hours! Join our Software Optimization for the Memory Subsystem Workshop taking place from May 18th to May 21st. Click here to express interest or register. |
The big O notation has been with program development since the inception of computer science, long before computers became accessible to common folks. It is all about counting: you count the operations, and you represent them as a function of the input size. A short example to refresh your memory (if you are familiar with calculation complexity, skip this section):
int binary_search(int* array, int number_of_elements, int key) {
int low = 0, high = number_of_elements-1, mid;
while(low <= high) {
mid = (low + high)/2;
if(array[mid] < key)
low = mid + 1;
else if(array[mid] == key)
return mid;
else if(array[mid] > key)
high = mid-1;
}
return -1;
}
This is a binary search algorithm that performs a search on a sorted array. It does so by halving intervals: it picks a number from the middle of the array. In the image we are searching for the number 7, and the array size is 17. We pick the middle of the array, (position 8) and its value is 14. Since 7 is smaller than 14, we are looking in the left side of the array, between positions 0 and 7. We pick an element in the middle of the left side, which is position 3, and its value is 6. Ok, now this value is smaller than the value we are looking for, so we take the right subarray, between positions 4 and 7. We repeat the same process of picking the element at the middle of the subarray, checking if it is bigger or smaller than the value we are searching, and halving the size of the subarray.
In this example, in the first step, the size of the subarray is n, in the second step the size of the subarray is n/2, in the third step it is n/4, etc. until we get to the subarray with the size 1. Since each subarray access is one step, the total number of steps is proportional to log2(n). And the complexity of this algorithm is O(log2(n)) .
Typical complexity of most common algorithms:
- Iterating through an array or a linked list of size n – complexity is O(n). The same applies to operation find on unsorted containers; we need roughly the same number of steps as the size of the array. The same also applies to simple processing elements of the array: calculating sums, manipulating individual elements of the array etc.
- Binary search in a sorted array – complexity O(log2(n)) – already explained why.
- Sorting an array – simple implementations (bubble sort or insertion sort) have complexity O(n2) since, for each element, we need to iterate until the end of the array. More complex implementations (quicksort for instance) have O(n log2(n)).
- Accessing an element in a hash map – complexity O(1) – the hash function calculation and access to the hash map entry is independent of the size of the hash map.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
How useful is the Big-O in modern systems?
The usefulness of big O notation is obvious when comparing two algorithms with different big O values working on a huge input. If the input is big enough, the algorithm with O(log2(n)) complexity will always beat the algorithm with O(n) complexity. But what happens when the complexities are the same? And what happens when the input is not huge?
Big O notation comes down to counting operations and then removing all the constants until only pure letters remain. But when the input is not too large, or two algorithms have the same complexity, the constants are really what matters.
In modern computer systems, there are some operations, that are almost free, and others that are very expensive. Examples of cheap operations are, for example, additions or subtraction. Examples of expensive operations are integer division, integer modulo, or loads from memory or stores to memory that miss the data cache. In big O notation, all these represent constants and they do not appear there. Let’s see a few examples:
Iterating through an array vs iterating through a linked list
Both of these algorithms have the same complexity O(n), but when it comes to performance, they are different like chalk and cheese. Iterating through an array has a very predictable memory access pattern. The underlying hardware recognizes this and prefetches data from the memory before it is needed. It is difficult to get better than that.
On the other hand, iterating through a linked list will typically experience a much higher data cache miss rate. We don’t know the address of the next element while we are processing the current element; this information becomes available only after dereferencing the next pointer. And what we don’t know, neither does the hardware. Unless you are lucky, a memory access will typically result in a data cache miss and a delay of 200 cycles (compared to no delay with arrays).
Additional benefit of using the arrays is that the compiler can often use vector instructions (SIMD instructions) to process the elements of the array, which additionally speeds up the computation.
Summing up 10 million integers took 4 ms with an array and 57 ms with a linked list. After we shuffled the linked list the runtime was much worse: 1545 ms. For those lists that are allocated once and not modified after that, you can expect the faster speed; if the list is modified a lot the runtime will be worse.
Text editors are known for having to process a large amount of data with quick addition and removal. The way they do it: gap buffers – arrays with reserved space to allow efficient addition and removal. More information about that here. We investigated a faster implementation of a linked list where two or more elements are kept in a single node in the article about data cache misses.
More information about linked list vs array performance can be found here.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
Same Big-O complexity, different speed, or how does std::sort work?
There are two common sorting algorithms with O(n log(n)) complexity, one is quicksort and the other is heapsort. In most cases quicksort is two to five times faster. And why? Quicksort picks a pivot element (which is in the essence the middle element), and that iterates through the array to split it into two parts: the part that is smaller than the pivot on the left and the part that is larger than the pivot on the right. Then it recursively does the same for the left and right subarray.
The memory access pattern of quicksort is very predictable, the hardware predictor recognizes it and prefetches the data before it is needed. On the other hand, the heapsort algorithm builds a heap out of an array: an operation that requires a lot of random access to the array where the hardware is helpless to determine the access pattern.
However, the quicksort algorithm comes with a caveat. Picking the pivot is crucial. If we keep picking a wrong pivot, we end up with an algorithm that has O(n2) runtime. Which is much worse for a large input. Heapsort doesn’t have this problem.
In our measurements, with a random array, quicksort took 2,4 seconds to sort an array of 10 million elements, and heapsort took 5.3 seconds.
Standard library’s std::sort takes a hybrid approach: it will try quicksort a few times, and if the sorting is not progressing well, it will switch to heapsort; an algorithm known as introspective sort. A nice idea, isn’t it?
Sorting a really small array
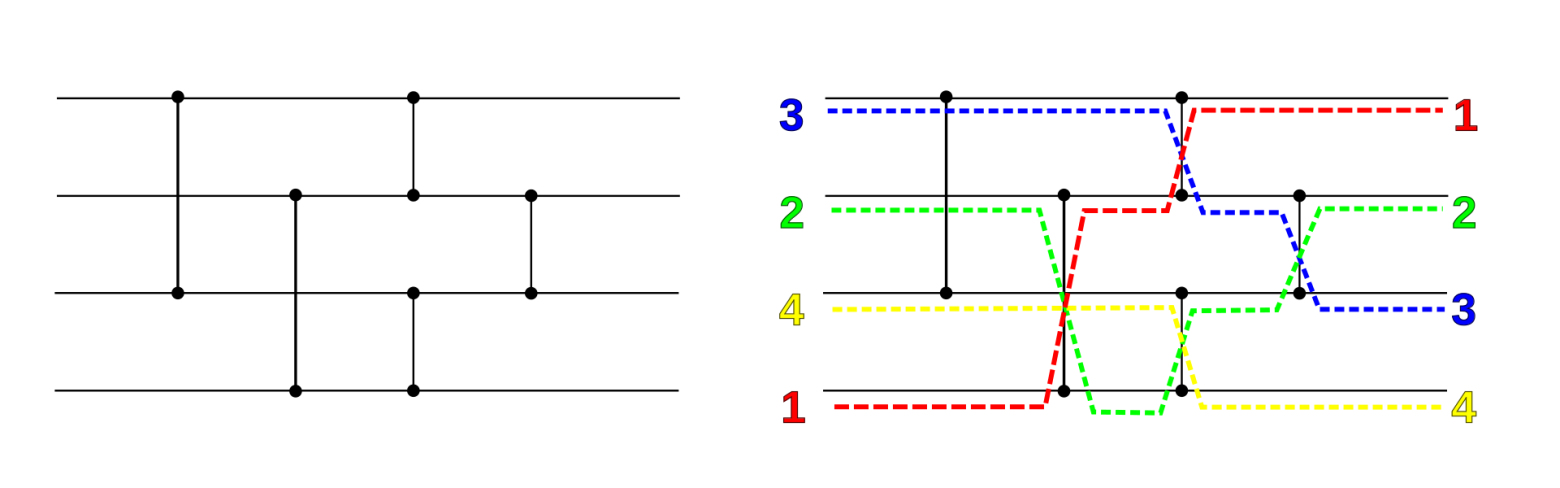
Let’s say we want to sort an array of four elements. Big O notation says nothing about this. We investigated three approaches: quicksort, insertion sort, and a sorting network. For those unfamiliar with sorting networks, an example is given in the picture:

A sorting network consists of wires and comparators. Every wire carries one value. In the above image, wires run from left to run and comparators connect two wires. When two values hit the comparator, at the output of the comparator the values will switch wires if and only if the value in the upper wire is greater than the value in the lower wire. Or to put it in other words, at the output of the comparator, the upper wire will carry the smaller value, and the lower wire will carry the higher value.
Here is a sorting network algorithm that sorts four numbers, according to the sorting network in the previous image:
void sorting_network_sort4(int a[]) {
swap_if_greater(a[0], a[2]);
swap_if_greater(a[1], a[3]);
swap_if_greater(a[0], a[1]);
swap_if_greater(a[2], a[3]);
swap_if_greater(a[1], a[2]);
}
The sorting network might seem like a lot of instructions, but here is the catch: sorting network doesn’t have branching, and can be implemented either with MIN and MAX instructions or conditional swap instructions. We already talked about branching in the previous article, but to stress it again: branching is expensive with modern processors because of branch prediction misses. Getting rid of the branches should in principle mean better performance.
We made a test to measure the performance difference. We created an array of 10 million elements, then we wanted to sort all pairs of four. The quicksort version took 188 ms, the insertion sort took 98 ms and the sorting network took 10 ms.
Summary
Big-O notation is just a beginning in understanding algorithm behavior, but there is much more than that. Modern processors make theoretical reasoning about algorithm performance much more difficult; only after measuring with the real-world data can we say which algorithm or data structure is actually faster.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
Featured image taken from Wikipedia.