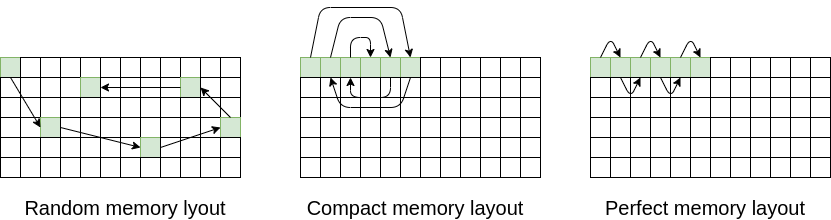
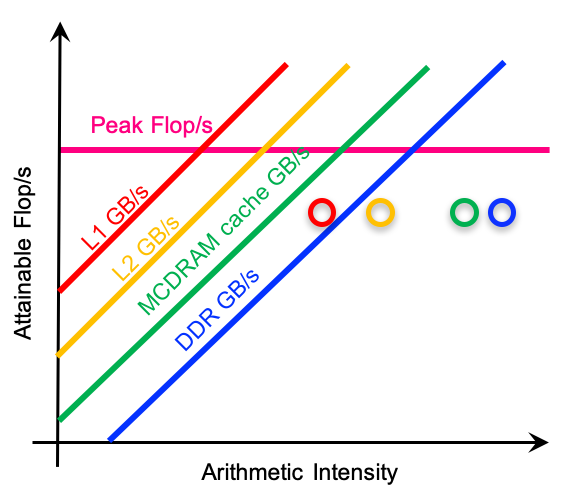
This is the last memory optimization that we are covering in this blog. You can see the full list of all memory subsystem optimization that we covered earlier here. Definitely a read for anyone who is trying to improve performance of memory intensive software. In this post, we are covering a few remaining optimization techniques…