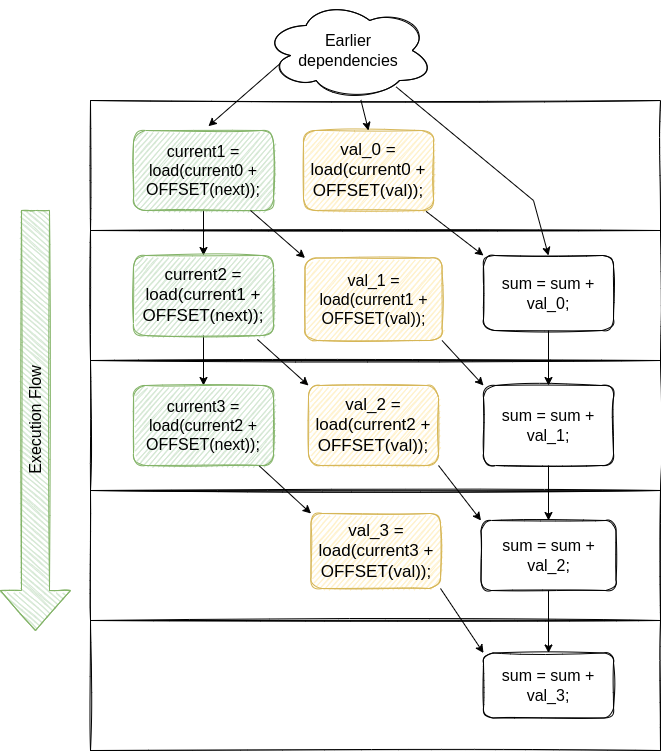
I was preparing an article about Highway – portable vectorization library by Google – so I ported a few examples from my vectorization workshop from AVX to Highway. One of the examples was vectorized binary search. I assume most readers are familiar with simple binary search. It looks something like this: We take a lookup…